集群管理
📄字数 7.5K
👁️阅读量 加载中...
数据库集群由多个节点组成,每个节点根据资源和部署需求,可灵活承担一个或多个角色(如控制、查询、工作、存储、变更记载),协同完成请求接入、任务调度和数据处理。通过职责划分与标准通信协议,系统实现了高可用、易扩展的分布式架构。
集群支持运行时动态管理,各节点通过心跳检测和广播机制保持元信息一致。控制节点负责统一管理元信息和协调其他节点,确保各角色高效协作。管理员可通过命令或系统虚表查看集群状态,并支持在线添加、下线和删除节点,以满足弹性扩容与故障恢复的需求。
系统支持多种扩容方式,包括从非分布式部署升级为分布式集群,在运行中动态增加节点等,其中在线扩容可在不中断服务的情况下完成。新增节点加入后,可自动同步配置并参与计算与存储任务。控制节点自动协调资源,确保系统平滑扩展。
为防止脑裂等极端异常导致的数据不一致,系统引入了节点降级机制:当控制节点检测到与集群中其他节点完全失联时,将自动进入只读模式,暂停业务写入,以保障数据一致性与系统安全。
一、节点角色
1.1 角色简介
为实现高可用、弹性扩展与负载隔离,集群节点被划分为多个功能角色。每个角色专注于特定任务,通过职责解耦与统一协议协作,共同完成请求接入、调度与数据持久化。各角色既可独立部署,也可部署在同一节点上,以适应不同规模和资源约束下的部署需求。
主要角色包括:
- 控制角色(Master):统一管理集群的元信息与运行状态,负责节点注册、版本管理、故障处理、数据均衡以及全局锁服务,是集群中各类角色协同运行的核心。
- 查询角色(Query):客户端请求的接入入口,负责建立连接、接收请求并进行初步解析与校验,再将任务转发至工作角色执行。不参与实际计算与数据处理。
- 工作角色(Work):负责具体的任务执行,可能将任务拆分为多个子任务,分配给其他工作角色以实现并行处理。其工作流程包括从任务队列获取请求,拉取 SQL,生成执行计划,向控制角色请求元信息,并与存储角色交互以完成数据读取与写入。对于数据变更操作,工作角色会将修改内容发送至变更记载角色(同步写入本地缓冲区,异步等待确认接收),以支持后续的审计、备份与增量恢复。
- 存储角色(Storage):负责数据版本的持久化存储,以及响应工作角色的读写请求。仅维护本地数据版本,所有版本的全局管理工作由控制角色统一调度。
- 变更记载角色(Gather):异步接收由工作角色提交的变更操作及其内容,并将其持久化保存,用于审计、备份与增量恢复。
1.2 请求执行流程
各类角色协同完成用户请求的接收、调度与执行。下图展示了一个典型 SQL 请求从客户端接入到最终完成执行的全过程,清晰展现了查询、控制、工作、存储、变更记载等角色在各阶段的交互时序。该流程体现了系统架构中的“计算与存储分离、接入与执行解耦”设计思想,有助于深入理解各角色在执行路径中的职责分工与协同机制。
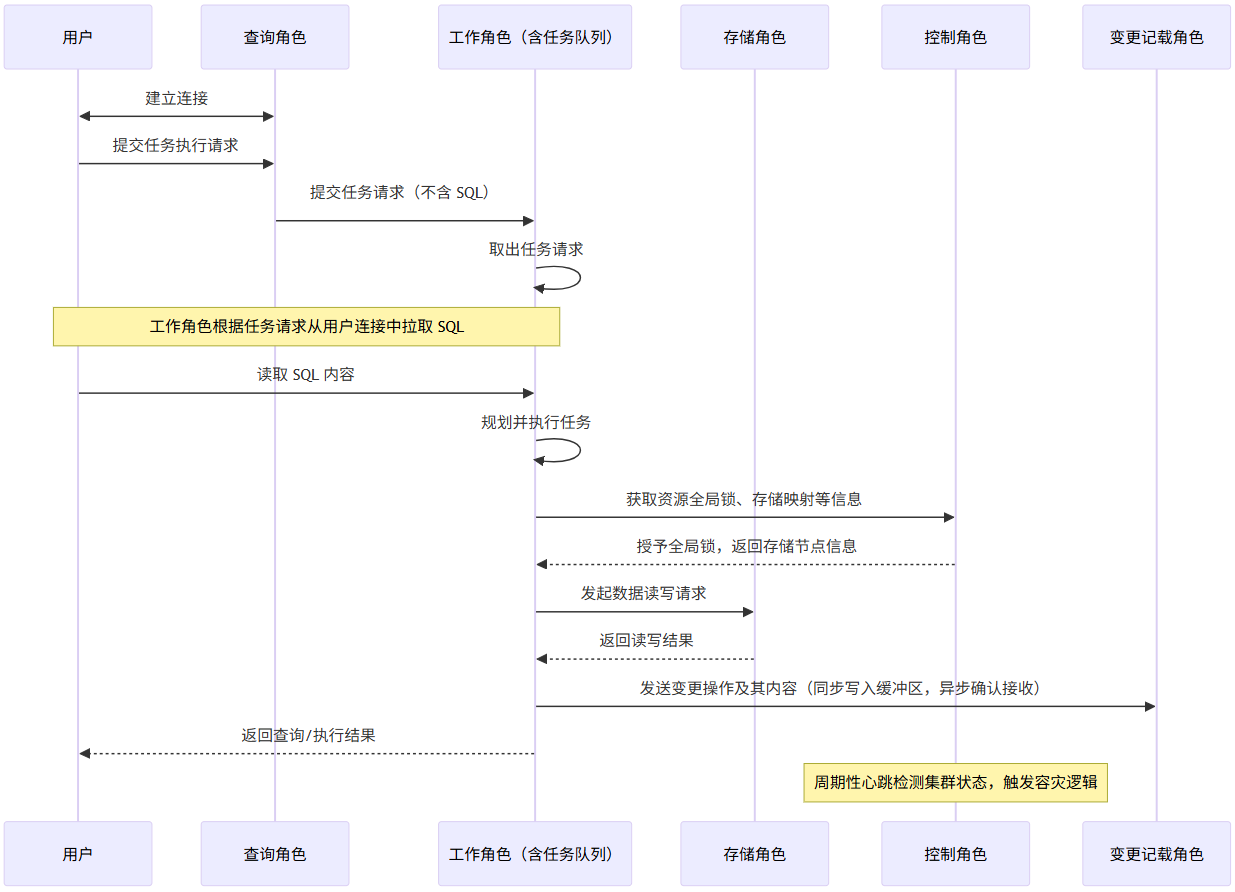
图 1.1 集群中各角色协作处理 SQL 请求的时序图
1.3 角色部署说明
在角色划分的基础上,角色部署需满足一定约束,以保障系统的可用性与协同效率:
- 控制角色:
- 集群中仅支持部署一组控制角色,由一个主(Master)和一个备(Standby)组成冗余对。主控制角色负责实际执行控制相关职责,包括元数据协调、存储均衡、节点心跳检测等任务,备角色实时同步状态,并在主角色故障时自动接管,以确保控制功能不中断。
- 主备角色必须部署在两个独立节点上,并且节点号必须相邻(即 n 和 n + 1)。建议采用默认配置:部署在 1 号与 2 号节点。
- 查询角色与工作角色:
- 必须部署在同一节点上,以支持从连接中拉取 SQL 的协作模式。
- 变更记载角色:
- 最多允许部署在两个节点上。
除以上约束外,其余角色可按需自由组合部署,以适应不同业务负载与资源分布,灵活构建计算与存储拓扑。
提示
主控制角色和备控制角色所在节点,一般称作主控节点和备控节点,也可称作主master和副master。
二、状态与配置查看
集群的运行状态信息可以通过以下方式获取:
SHOW CLUSTERS命令:适合日常使用。无需切换至系统库,也无需权限认证。使用说明见:CLUSTERS。SYS_CLUSTERS系统虚表:适合脚本化处理或复杂查询。需切换到系统数据库并具备访问权限。使用说明见:SYS_CLUSTERS。
两者展示的数据内容一致,均源自当前节点内存中维护的集群元信息(即全局配置以及所有已知节点的状态、角色、网络信息等)。
集群的静态配置信息则保存在集群配置文件中,涵盖了全局配置与各节点的本地配置,详细说明参见:系统集群文件。
提示
集群元信息和配置文件的维护:
- 每个节点在启动后首先加载本地
cluster.ini配置文件。除主控节点外的其他节点在加入集群时,会从主控节点拉取最新的集群元信息并更新自身内存和cluster.ini文件。集群运行过程中,各节点通过心跳检测与广播机制维护这一份核心字段高度一致的集群元信息副本。 - 主控和备控节点在此基础上还额外维护控制字段,如主备镜像信息等。
三、节点管理操作
本章介绍如何使用 ALTER CLUSTER 命令动态管理集群元信息,包括添加节点、下线节点和删除节点等操作。其中,下线节点和删除节点仅在 V12 版本中支持,V11 仅支持添加节点。
- 添加节点(
ADD NODE):将新节点信息广播给所有存活节点,更新它们内存中的集群元信息和cluster.ini文件。 - 下线节点(
SET NODE node_id OFFLINE):通知目标节点进程执行一次检查点操作后立即退出。随后,主控节点通过心跳机制检测到该节点不可达,并将其状态标记为离线后广播给其他节点。此过程中不会修改cluster.ini文件。 - 删除节点(
DROP NODE):通知所有节点从内存元信息和cluster.ini中移除该节点的相关信息。删除节点前应先下线节点。
这些命令仅修改逻辑上的集群元信息和配置文件,不会自动创建或删除节点目录。完整的扩容流程见:集群扩容。
所有节点管理操作必须在系统库中执行,且当前用户必须为 SYSDBA 或具备 DBA 权限,否则命令将被拒绝执行。
3.1 语法格式
3.2 参数说明
node_id:节点号。node_desc:节点描述(配置)信息。具体格式为一串用空格分隔的键值对,例如:'RACK=0001 PORTS="192.168.2.236:19114" ROLE=SQW LPU=3 STORE_WEIGHT=3 STATE=DETECT'。OFFLINE: 离线状态。
3.3 示例
提示
这里的示例不实际创建和删除节点目录,只演示修改内存中的集群元信息。
- 增加节点。
sql
-- 集群当前由3个节点组成,添加4号节点
SQL> ALTER CLUSTER ADD NODE 4 DESCRIBE 'RACK=0001 PORTS="192.168.2.236:19114" ROLE=SQW LPU=3 STORE_WEIGHT=3 STATE=DETECT';
-- 查看集群信息,此刻4号节点为无效状态(尚未启动或尚未加入集群)
SQL> SELECT node_id,node_ip,node_type,node_state FROM SYS_CLUSTERS;
+---------+------------------------------+-----------+------------+
| NODE_ID | NODE_IP | NODE_TYPE | NODE_STATE |
+---------+------------------------------+-----------+------------+
| 1 | 192.168.2.236:19111 | 29 | 2 |
| 2 | 192.168.2.236:19112 | 31 | 2 |
| 3 | 192.168.2.236:19113 | 60 | 2 |
| 4 | 192.168.2.236:19114(invalid) | 28 | 4 |
+---------+------------------------------+-----------+------------+- 下线节点,然后删除节点。
sql
-- 下线4号节点
SQL> ALTER CLUSTER SET NODE 4 OFFLINE;
-- 删除4号节点
SQL> ALTER CLUSTER DROP NODE 4;
-- 查看集群信息,节点删除成功
SQL> SELECT node_id,node_ip,node_type,node_state FROM SYS_CLUSTERS;
+---------+---------------------+-----------+------------+
| NODE_ID | NODE_IP | NODE_TYPE | NODE_STATE |
+---------+---------------------+-----------+------------+
| 1 | 192.168.2.236:19111 | 29 | 2 |
| 2 | 192.168.2.236:19112 | 31 | 2 |
| 3 | 192.168.2.236:19113 | 60 | 2 |
+---------+---------------------+-----------+------------+注意
- 为确保数据一致性和系统安全,不允许直接删除活跃节点。应先将节点下线,确认其已退出集群后(所有存活节点的
EVENT.LOG或stdout.txt中输出类似Node i deaded done或On node(i) dead done的日志),再执行删除操作。
四、集群扩容
本章介绍 XuguDB 在不同部署形态下的扩容方式,包括从非分布式部署升级为分布式部署、分布式部署系统的扩容,以及相关操作流程与注意事项。
4.1 非分布式部署系统扩容
适用于将已有的非分布式部署系统迁移升级为支持多节点的分布式部署系统的扩容场景(即从传统单机模式切换为分布式架构)。
操作步骤:
- 准备分布式环境:使用分布式版本安装包,规划集群规模(如 3 节点、5 节点),参考部署 XuguDB 分布式版完成集群搭建。
- 使用迁移工具导入数据:停止原单机服务,使用官方提供的迁移工具,将单机中的数据迁移至新集群中。参见《迁移工具用户指南》。
- 切换服务入口:应用系统切换为连接新建的分布式集群,即完成扩容。
注意事项:
- 新部署的分布式集群版本应不低于原单机版本。
- 数据迁移过程为离线迁移,需暂停业务写入。
- 建议在测试环境充分验证后进行迁移。
4.2 分布式部署系统扩容
本节介绍对分布式部署系统,如何通过离线或在线方式增加节点。
提示
离线扩容和在线扩容均支持一次扩容多个节点:
- 对离线扩容,先准备好多个新节点,然后启动所有节点(包括已有节点和新节点)。
- 对在线扩容,先分别执行多条节点添加命令,然后准备并启动所有新节点。
4.2.1 离线扩容
适用于以下场景:
- 系统以分布式版本部署,但仅包含一个节点,需扩容为多节点。
- 多节点分布式部署的系统,需要执行扩容操作(此类场景亦支持在线扩容,建议优先选择在线方式)。
操作步骤:
- 停止服务并修改配置:停止应用和数据库服务,在所有现有节点的
cluster.ini中追加新增节点的配置信息,例如NID=0003 RACK=0001 PORTS='127.0.0.1:10000' ROLE='SQWG' LPU=1 STORE_WEIGHT=3 STATE=DETECT;。配置项说明可参考系统集群文件。 - 准备新节点:将任一现有节点的
BIN和SETUP目录拷贝到新增节点服务器,并修改xugu.ini和cluster.ini中的监听端口、节点编号(MY_NID)等信息。 - 启动所有节点:所有节点统一执行启动命令,系统将自动完成节点注册、元信息同步与版本修复。
- 验证扩容成功:通过
SHOW CLUSTERS命令或查询SYS_CLUSTERS确认新增节点是否正常在线,并参考4.3 存储版本修复判断版本修复是否完成。

图 4.1 分布式部署系统离线扩容
注意事项:
- 扩容期间服务不可用。
- 所有节点配置(除监听端口、节点编号等)应保持一致。
- 版本修复是离线扩容的必经步骤,应在明确完成后再恢复业务。
4.2.2 在线扩容
适用于当前已运行的多节点分布式部署的系统,通过命令添加节点并启动服务,不中断业务运行。
操作步骤:
添加节点:以
SYSDBA或具备DBA权限的用户登录任一节点的系统数据库,执行以下 SQL 命令。sqlALTER CLUSTER ADD NODE node_id DESCRIBE node_desc;准备新节点:将现有节点的
BIN和SETUP目录拷贝到新增节点服务器,并修改xugu.ini和cluster.ini中的监听端口、节点编号(MY_NID)等信息。启动新节点:执行启动命令,新节点自动注册到集群中,并完成心跳建立、元信息同步等过程。
验证扩容成功:通过
SHOW CLUSTERS命令或查询SYS_CLUSTERS确认新增节点是否正常在线(不需要确认存储版本修复是否完成)。

图 4.2 分布式部署系统在线扩容
注意事项:
- 添加节点前建议执行
SHOW CLUSTERS确认当前集群状态与节点编号。 - 节点配置必须正确,特别是
MY_NID不能与现有节点冲突。 - 主控节点必须在线,集群通信正常。
4.3 存储版本修复
提示
本节仅简要说明扩容过程中涉及的存储版本修复流程。不介绍节点故障引起的版本修复和版本自动均衡。
在扩容过程中,系统会自动执行版本修复,以确保数据的冗余性和可用性。该过程通常是扩容操作中最耗时的部分。
- 当新节点加入集群后,若原有版本不足,系统会自动在新节点上创建数据版本。
版本修复在后台异步执行,仅对正在修复的全局存储加锁,不会阻塞整体读写,因此对业务影响较小。
如何判断修复已完成:
可通过以下 SQL 语句判断修复是否完成:
sql
SELECT COUNT(*) FROM SYS_GSTORES WHERE store_sta != 41;- 查询结果为 0 表示所有全局存储的版本状态正常,修复已完成。
store_sta = 41表示该全局存储的所有版本处于正常状态。
注意
store_sta的正常值取决于集群中的存储节点数量与版本数设置。用户存储的版本数由系统参数default_copy_num控制,系统存储的版本数固定为 3。- 例如:若版本数为 3,且集群中有足够的存储节点以承载 3 个版本,则仅当某个全局存储的 3 个版本全部处于正常状态时,其
store_sta才为 41。 store_sta的详细含义可参考 SYS_GSTORES 系统表说明。
补充说明:
- 版本修复仅在版本不足时触发:系统会在扩容后检测全局存储的版本状态,若存在版本不足的情况,才会在新节点上创建版本以补齐。
- 无需强制等待修复完成:若扩容过程中允许业务写入(如在线扩容),可按需检查修复状态,无需强制等待全部完成。
4.4 常见问题与排查建议
| 问题描述 | 原因分析 | 处理建议 |
|---|---|---|
| 节点无法加入集群 | - 配置文件中 MY_NID 设置错误- 监听端口/通讯端口被其他服务占用 | - 检查节点配置 - 使用 netstat 等工具确认端口无冲突 |
启动后节点状态为 INVALID | - 节点与主控之间心跳连接未建立 | - 检查网络连通性、防火墙策略,以及主控节点日志 |
| 执行添加节点命令报错 | - 节点编号已存在或描述冲突 - 当前连接的不是系统库 - 当前用户不是 SYSDBA 或不具备 DBA 权限 | - 检查并修改当前添加节点的节点编号或描述信息 - 确保使用系统库 - 确保具备权限 |
| 执行删除节点命令报错 | - 目标节点未成功下线 - 当前连接的不是系统库 - 当前用户不是 SYSDBA 或不具备 DBA 权限 | - 确保目标节点已正常退出集群 - 确保使用系统库 - 确保具备权限 |
五、节点降级
5.1 降级机制概述
在分布式环境中,脑裂是指控制节点之间网络中断或故障后,各自误判对方不可用,从而独立执行业务操作,导致数据不一致。为防止此类风险,系统引入节点降级机制,以确保集群在失联或状态异常时主动进入受限状态,禁止业务写入,从而保障数据一致性。
节点降级机制由参数 enable_node_degrade 控制,详细说明参见:enable_node_degrade。
提示
降级机制仅适用于控制节点(主控与备控)。普通计算与存储节点不会触发此机制。
5.2 降级触发条件
只有在以下情况同时满足时,控制节点才会主动进入降级状态:
- 当前集群中注册的节点总数大于 1(包括当前不在线的节点)。
- 且仅剩下本节点自身存活,其他节点均因心跳超时被判定为不存活(可能由节点退出或网络异常导致)。
一旦触发降级,控制节点会将内存变量 CLUSTER_FAULT_LEVEL 设置为非零值,系统进入受限(降级)状态。该变量的说明参见:CLUSTER_FAULT_LEVEL。
5.3 降级后行为与影响
在降级状态下,控制节点进入只读模式,禁止执行所有写操作(包括 DDL 与 DML)。以下列出部分典型影响:
- 拒绝用户写请求。
- 拒绝节点加入。
5.4 降级恢复流程
下面以三节点集群为例说明降级恢复流程。对于其他节点个数集群的降级恢复,请联系虚谷技术支持获取指导方案。
前提条件:
- 已定位并解决引发降级的根因(如网络中断、节点故障等)。
- 当前集群中至少有一个控制节点处于活动状态。若所有控制节点均不处于活动状态,可直接重启所有节点,此时无需执行后续恢复步骤。
恢复步骤:
重启除主控节点外的所有节点。若多个控制节点处于活动状态,应手动指定其中一个节点作为主控节点,不重启该节点,重启另一个控制节点。
清除降级标志:在主控节点上以
SYSDBA用户执行以下命令,解除降级状态。sqlSET CLUSTER_FAULT_LEVEL TO 0;执行后,该控制节点将允许节点加入,系统退出只读模式。
验证集群状态:使用
SHOW CLUSTERS或查询SYS_CLUSTERS,确保所有节点状态恢复正常。
六、节点故障与恢复
数据库节点在运行过程中可能因硬件故障、操作系统异常或资源压力等原因发生异常中断。节点故障是集群中的严重事件,可能影响服务可用性与数据冗余,需及时定位并处理,以保障系统稳定性与数据完整性。
6.1 故障排查建议
节点发生故障后,应优先分析故障原因。常见排查路径包括:
- 检查硬件故障:包括磁盘损坏、电源异常、主板故障等。
- 分析系统日志:查看操作系统日志(如
dmesg、/var/log/messages等),确认是否存在内核级别错误或资源回收行为。 - 查看数据库日志:如
EVENT.LOG等,重点分析节点退出前的最后操作和关键报错信息。 - 排查资源使用情况:重点关注 CPU 和内存指标。某些场景下,业务压力突增可能导致系统资源耗尽,操作系统触发 OOM(Out-Of-Memory)机制,错误地将数据库进程终止。
警告
节点故障通常为重大事件,应及时通知数据库管理员介入处理,避免影响业务连续性。
6.2 故障恢复方式
控制节点(主控或备控)在网络隔离或故障后,可能会触发降级机制,进入只读模式(详见节点降级)。此时即便节点恢复连通,也需按降级恢复流程手动清除降级标志后,才能恢复正常服务。
根据故障严重程度与集群当前状态,可采用以下两种恢复方式:
- 重启故障节点。若故障节点机器仍可访问,排查并修复问题后即可重启节点服务。系统将自动恢复心跳连接并同步元信息,节点状态将恢复为在线。
- 替换为新节点。若原节点无法恢复,可将其从集群中移除,并添加一台新节点接替其职责。如遇节点添加失败等问题,可参考:4.4 常见问题与排查建议。
在主控节点执行以下命令,删除故障节点信息:
sqlALTER CLUSTER DROP NODE node_id;准备一台新机器,部署与原节点一致的软件与配置。
在主控节点执行添加命令:
sqlALTER CLUSTER ADD NODE node_id DESCRIBE node_desc;启动新节点服务,系统将自动恢复数据版本并更新集群元信息。