SQL FAQ
📄字数 14.6K
👁️阅读量 加载中...
本文档记录虚谷数据库中常见的SQL相关问题,按照问题之间的相关性,分为以下几类:
- 数据查询与修改
- 数据定义与维护
- 存储、数据库对象、数据库资源监控、连接、运维相关
- 诊断、运维与性能
目录
数据查询与修改
如何在字符串中包含单引号?
sql
-- 正常写法:单引号 → 用两个单引号转义
INSERT INTO emp(name, city)
VALUES ('O''Reilly', 'Beijing');
-- 嵌套在动态 PL/SQL 中的写法示例
-- 中间字符串带了3对单引号,其中一对单引号被转义成了不带特殊含义的单引号字符,插入表中name显示为‘xiaohei’
execute dbms_scheduler.create_job(
'test1',
'plsql_block',
'declare begin insert into test1 values(11,''xiaohei'',15,''beijing'');end;',
0,
current_date,
'freq=weekly;interval=1;',
'2030-11-11 10:10:10',
'default_class',
false,
false,
'这是一个测试用例'
);分组统计后如何选出每组的第一条记录?使用group by之后,如何获取非group的字段?
sql
SQL> CREATE TABLE t_exp2(c1 INT,c2 INT);
SQL> INSERT INTO t_exp2 VALUES(1,RAND)(1,RAND)(1,RAND);
SQL> INSERT INTO t_exp2 VALUES(2,RAND)(2,RAND);
--查询:
SELECT c1, c2
FROM (
SELECT c1,
c2,
ROW_NUMBER() OVER (PARTITION BY c1 ORDER BY c2 DESC) AS rn
FROM t_exp2
) t
WHERE rn = 1;
+----+------------+
| C1 | C2 |
+----+------------+
| 1 | 1333893513 |
| 2 | 1702255141 |
+----+------------+提示
当单表 > 10 万行且未在 PARTITION BY / ORDER BY 列上建索引时,窗口函数会触发全表排序,代价较高。
如需对超大数据集(500 万行以上)分组抽样,建议把查询写成 “分组子查询 + EXISTS / IN(或等值 JOIN)” 的形式。
sql
SELECT e.*
FROM t_exp2 e
JOIN (SELECT c1, MAX(c2) AS max_c2
FROM t_exp2
GROUP BY c1) m
ON e.c1 = m.c1 AND e.c2 = m.max_c2;使用group by之后,获取非group的字段:
sql
SQL> create table test_0928(id int,name varchar);
SQL> insert into test_0928 values(1,'aaa');
SQL> insert into test_0928 values(1,'bbb');
SQL> insert into test_0928 values(2,'ccc');
SQL> insert into test_0928 values(2,'ddd');
SQL> insert into test_0928 values(3,'eee');
-----虚谷
SQL> SELECT id,name FROM (SELECT id,name,ROW_NUMBER() OVER (PARTITION BY id ORDER BY id )rn FROM test_0928)t WHERE t.rn = 1;
+-------------+---------------+
| ID(INTEGER) | NAME(VARCHAR) |
+-------------+---------------+
| 1 | aaa |
| 2 | ccc |
| 3 | eee |
+-------------+---------------+
-----MySQL
select id,ANY_VALUE(name)
from test_0928
group by id;注意
自 V12 起,虚谷数据库 已提供基础窗口函数(ROW_NUMBER / RANK / DENSE_RANK 等)。当前仅支持单机场景、简单 PARTITION BY 语法;对于多级嵌套或分布式执行尚在优化中。
如何删除重复记录?
sql
-- 保留 ROWID 最大的一行
DELETE FROM t_exp3
WHERE ROWID NOT IN (
SELECT MAX(ROWID)
FROM t_exp3
GROUP BY c1, c2, c3);提示
性能衡量:当表行数过大时,可能存在性能问题,建议在排序列、分组列上建立索引。
如何在控制台批量执行 .txt 脚本?
通过控制台输入EXECFILE 文件绝对路径语句完成,
bash
execfile /opt/sql/initial_data.txt日期加减的几种写法
| 目标 | 示例 |
|---|---|
| 年月日加减 | select sysdate +/- interval '1' year/month/day; |
| 时分秒加减方式1 | select sysdate +/- interval '1' hour/minute/second; |
| 时分秒加减方式2 | select sysdate +/- 1/24,1/60/24,1/60/60/24; |
注意
日期加数字时,默认加减day。
详细的时间类型运算,请参阅时间类型运算符。
如何插入 BLOB / CLOB?
sql
CREATE TABLE test_lob(a BLOB, b CLOB);
-- 控制台专用占位符:
INSERT INTO test_lob VALUES (?,?); <# /home/imgs/logo.png <% /home/texts/manual.txt| 占位符 | 适用类型 | 说明 |
|---|---|---|
? | 待插入的大对象值 | 参数化表示 |
<# | BLOB | 以 二进制流 方式加载文件 |
<% | CLOB | 以 字符流(客户端编码)加载文件 |
一次新增多个列
sql
ALTER TABLE student
ADD sex CHAR(4), address VARCHAR(60);主键如何设置为自增?
对主键字段设置自增序列,无需手动序列。
sql
-- ID作为主键,同时设置自增
CREATE TABLE t_identity(
id INT IDENTITY(1,1) PRIMARY KEY,
name VARCHAR(30)
);禁用 / 启用约束
sql
ALTER TABLE orders DISABLE CONSTRAINT fk_orders_customer;
ALTER TABLE orders ENABLE CONSTRAINT fk_orders_customer;详细用法请参阅约束。
一次性插入多列 LOB
请参阅如何插入-blob--clob。
TO_NUMBER函数精度丢失
问题:当TO_NUMBER函数的输入参数为DOUBLE类型时,其结果可能出现精度丢失,导致转换后的数值与原始DOUBLE值存在细微差异。
原因:数据库会执行隐式类型转换。其转换路径如下:DOUBLE → VARCHAR → NUMERIC。
第一步的隐式转换:将DOUBLE类型转换为字符串时,会将精度截断至15位有效数字,被截断的字符串再转换为NUMERIC类型,因此最终结果无法保持原始DOUBLE变量的全部精度。
因此,不建议直接将DOUBLE类型数据传入TO_NUMBER函数进行高精度转换。如需精确计算,应确保数据以字符串形式传入,或直接使用NUMERIC类型进行处理。
数据定义与维护
查询表的外键依赖关系
sql
-- 其中第一列为外键表,第二列为外键表引用的主键表
select ut1.table_name as fk_name,ut2.table_name as pk_name
from
user_constraints uc
join
user_tables ut1
on
uc.table_id=ut1.table_id
join
user_tables ut2
on
uc.ref_table_id=ut2.table_id;数值超界错误如何定位?
- 列定义与模型映射:确认程序中的类型(如
int32 / decimal(10,2))是否与数据库一致。 - 超长数据:检查导入文件或上游接口是否传入异常值。
需要在程序中排查数据模型对以上两点的处理,同时需要关注入库的数据是否正确。
表名、列名批量进行大小写转换
以下脚本根据模式名动态生成重命名语句:
plsql
DECLARE
v_schema VARCHAR2(128) := 'MY_SCHEMA';
v_sql VARCHAR2(4000);
BEGIN
FOR t IN (
SELECT table_name FROM dba_tables
WHERE schema_name = v_schema) LOOP
v_sql := 'ALTER TABLE "' || v_schema || '"."' || t.table_name ||
'" RENAME TO "' || LOWER(t.table_name) || '"';
EXECUTE IMMEDIATE v_sql;
END LOOP;
END;
/提示
建议使用小写对象名以获得跨数据库的一致性;如必须大写,可将 LOWER 换成 UPPER。
EXPLAIN 路径规划字段说明
EXPLAIN SELECT * FROM route_tab1 WHERE a1 = 88;
+------------------------------------------------------------------------------------+
| plan_path |
+------------------------------------------------------------------------------------+
| 1 BtIdxScan[(1 1) cost=10200,result_num=1000](table=ROUTE_TAB1)(index=TAB1_IDX1) |
+------------------------------------------------------------------------------------+| 标记 | 含义 |
|---|---|
1 | 步骤编号 |
(1 1) | 执行位置与顺序 |
cost=10200 | 估算代价,值越高表示 I/O 与 CPU 耗费越大 |
result_num=1000 | 预计输出行数 |
table=ROUTE_TAB1 | 访问对象 |
index=TAB1_IDX1 | 命中索引 |
提示
更多关于EXPLAIN的详细说明,请参阅EXPLAIN。
开启 / 关闭缓慢变更(SCD)
sql
ALTER TABLE customer_dim SET SLOW MODIFY OFF; -- 关闭
ALTER TABLE customer_dim SET SLOW MODIFY ON; -- 开启IF、DECODE、CASE 的兼容情况
当前已兼容MysqlIF函数使用。
或使用CASE WHEN:
sql
SELECT CASE WHEN score >= 90 THEN 'A'
WHEN score >= 80 THEN 'B'
ELSE 'C' END AS grade
FROM exam;查看表结构
sql
SELECT col_no, col_name, type_name,
TRUNC(scale/65536) AS precision,
MOD(scale,65536) AS scale,
not_null
FROM dba_columns
WHERE table_name = 'EMP'
ORDER BY col_no;查看序列(Sequence)信息
sql
SELECT schema_name, seq_name,
curr_val, max_val, min_val, step_val
FROM dba_sequences
WHERE schema_name = 'MY_SCHEMA';临时表如何删除
create temp table 创建的局部临时表其生命周期与会话一致,会话断开后就被清除。
想手动删除的话,执行drop table。
如何查询出某个模式下所有表名称
- 系统库下查询:可查询所有库下的表,需要在系统库(SYSTEM)下使用SYSDBA用户执行
- 查询当前库下所有的表,需要DBA权限
- 查询当前用户下所有的表
按需添加条件(WHERE a.schema_name='XXX')筛选即可
查看表是否存在约束
sql
select t.table_name,c.* from dba_constraints c join dba_tables t on c.table_id=t.table_id where TABLE_ID=(select table_id from dba_tables where table_name='表名');存储、数据库对象、数据库资源监控、连接、运维相关
存储查询
需要SYSDBA用户登录到SYSTEM(系统库)执行
- 堆表
sql
SQL> select count(*)*8||'M' from sys_gstores where head_no=(select t.gsto_no from sys_tables t join sys_schemas s on t.schema_id=s.schema_id and t.db_id=s.db_id inner join sys_databases d on t.db_id=d.db_id where t.table_name='表名' and schema_name='模式名' and d.db_name='库名');
+----------------+
| EXPR1(VARCHAR) |
+----------------+
| 0M |
+----------------+- 分区表
sql
SQL> select count(*)*8||'M' from sys_gstores where head_no in (select gsto_nos from sys_tables t join sys_partis p on t.table_id=p.table_id and t.db_id=p.db_id join sys_schemas s on t.schema_id=s.schema_id and s.db_id=s.db_id join sys_databases d on t.db_id=d.db_id and s.db_id=d.db_id where t.table_name='表名' and s.schema_name='模式名' and d.db_name='库名');
+----------------+
| EXPR1(VARCHAR) |
+----------------+
| 0M |
+----------------+表结构查询
- 堆表查询
sql
select t.table_name,t.table_id,c.col_no,c.col_name,c.type_name,trunc(c.scale/65536)::int as scale_1,mod(c.scale,65536) as scale_2,c.not_null,c.comments from dba_columns c,dba_tables t where t.table_id=c.table_id and c.db_id=current_db_id and t.table_name='表名' order by c.col_no;- 分区表查询
sql
select schema_name,col_name,parti_type,parti_num,parti_key,* from dba_columns c
inner join dba_tables t on t.table_id=c.table_id
inner join dba_schemas s on t.schema_id=s.schema_id
where schema_name='模式名'
and table_name='表名'
order by col_no;如何统计分区大小
sql
select mn.table_name,mn.parti_name,count(*)*8||'M' from sys_gstores s, (select t.table_name,p.parti_name,p.gsto_nos from sys_tables t join sys_partis p on t.table_id=p.table_id
and t.db_id=p.db_id join sys_schemas s on t.schema_id=s.schema_id and
s.db_id=s.db_id join sys_databases d on t.db_id=d.db_id and s.db_id=d.db_id
where t.table_name='表名' and s.schema_name='模式名' and d.db_name='库名') mn where s.head_no=mn.gsto_nos group by mn.table_name,mn.parti_name order by mn.parti_name;单张表数据大小统计
sql
SQL1:(TB)
select d.db_name,sn.schema_name,t.table_name,count(*)*8/1024/1024||'T' as cnt from sys_schemas sn,sys_tables t,sys_gstores s,sys_databases d where s.obj_id=t.table_id and sn.schema_id=t.schema_id and sn.db_id=t.db_id and s.db_id=d.db_id and sn.db_id=t.db_id and db_name='库名' and t.table_name='表名' group by t.table_name,sn.schema_name,d.db_name;
select d.db_name,sn.schema_name,t.table_name,count(*)*8/1024 || 'G' as cnt from sys_schemas sn,sys_tables t,sys_gstores s,sys_databases d where s.obj_id=t.table_id and sn.schema_id=t.schema_id and sn.db_id=t.db_id and s.db_id=d.db_id and sn.db_id=t.db_id and db_name='库名' and t.table_name='表名' group by t.table_name,sn.schema_name,d.db_name;查看某模式下的表、序列名、步长等
sql
select s.schema_name,t.table_name,c.serial_id,se.seq_name,se.curr_val,se.max_val,se.min_val,se.step_val from dba_tables t,dba_schemas s,dba_columns c,dba_sequences se where t.schema_id=s.schema_id and s.schema_name='USR_SOD' and c.table_id=t.table_id and c.serial_id > 0 and se.seq_id=c.serial_id;查看某个模式下的对应表的索引个数
此处用例中以TCZX_TY_EPLUS模式作为模式名示例,根据实际情况替换。
sql
select t.table_name,count(*) from dba_tables t,dba_indexes i,dba_schemas s where t.table_id=i.table_id and
t.schema_id=s.schema_id and t.db_id=s.db_id and t.db_id=i.db_id and s.schema_name='TCZX_TY_EPLUS' group by t.table_name order by t.table_name;查看某模式下所有存在序列的情况
此处用例中以SYSDBA模式作为模式名示例,根据实际情况替换。
sql
select s.schema_name,t.table_name,c.serial_id from dba_columns c,dba_tables t,dba_schemas s where t.schema_id=s.schema_id and s.schema_name='SYSDBA' and c.table_id=t.table_id and c.serial_id > 0;查询表索引信息
sql
select t.table_name,i.index_name,i.keys,case when i.is_primary is false and i.is_unique is false then 'idx' when i.is_primary is true then 'primary' when i.is_primary is false and i.is_unique is true then 'unique' end type
from dba_tables t,dba_schemas s,dba_indexes i where t.schema_id=s.schema_id and t.table_id=i.table_id and s.schema_name='USR_SOD' and regexp_like(t.table_name,'^SURF');查询表分区情况
sql
select t.table_name,t.parti_key,T.AUTO_PARTI_SPAN,DECODE(T.AUTO_PARTI_TYPE,1,'年',2,'月',3,'日') from dba_tables t,dba_schemas s where t.schema_id=s.schema_id and s.schema_name='USR_SOD' and regexp_like(t.table_name,'^SURF');查询列、列顺序
sql
SQL> declare
sql varchar;
a int;
na varchar;
begin
na:='AA';
sql:='select ';
a:=0;
for i in (select a.col_name from DBA_columns a,DBA_tables b,DBA_SCHEMAS c where c.schema_id=b.schema_id and a.table_id=b.table_id
and b.table_name=na and c.schema_name='USR_SOD' order by col_no) loop
if a=0 then
sql:=sql||i.col_name;
else
sql:=sql||','||i.col_name;
end if;
a :=a+1;
end loop;
sql:=sql||' from usr_sod.'||na;
send_msg(sql);
end;
/
select from usr_sod.AA查看线程工作内存高的SQL
sql
select d.db_name,sn.schema_name,t.table_name,count(*)*8/1024/1024 from sys_schemas sn,sys_tables t,sys_gstores s,sys_databases d where s.obj_id=t.table_id and sn.schema_id=t.schema_id and sn.db_id=t.db_id and s.db_id=d.db_id and sn.db_id=t.db_id and db_name='库名' and t.table_name='表名' group by t.table_name,sn.schema_name,d.db_name;查看线程状态
sql
SELECT STATE,COUNT(*) FROM SYS_ALL_THD_STATUS WHERE STATE>0 GROUP BY STATE;
SELECT NODEID,COUNT(*) FROM SYS_ALL_THD_STATUS where STATE=13 GROUP BY NODEID ORDER BY NODEID;查看版本修复情况
sql
select count(*) from sys_gstores where node_id1=4 and bit_and(store_sta,3)=3;
select count(*) from sys_gstores where node_id2=4 and bit_and(store_sta,12)=12;
select count(*) from sys_gstores where node_id3=4 and bit_and(store_sta,48)=48;
select count(*) from sys_gstores where node_id1 in (1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28) and bit_and(store_sta,3)=3;
select count(*) from sys_gstores where node_id2 in (1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28) and bit_and(store_sta,12)=12;
select count(*) from sys_gstores where node_id3 in (1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28) and bit_and(store_sta,48)=48;查看等待对象
- 查看等待对象
sql
SELECT WAIT_OBJ,COUNT(*) FROM SYS_THD_STATUS WHERE STATE=8 GROUP BY WAIT_OBJ;
3888:上面sql语句查询出来的sys_thd_status中的wait_obj,按实际查询得到的数据填充,此处为3888。
select *, bit_and(tranid,16777215) lockid from sys_trans where lockid in(3888);- 查看等待对象对应的表
sql
SELECT * FROM SYS_TABLES WHERE TABLE_ID IN (SELECT BIT_AND(WAIT_OBJ,4294967295) FROM (SELECT DISTINCT WAIT_OBJ FROM SYS_ALL_THD_STATUS WHERE WAIT_OBJ>0) A);查询长事务
sql
select * from sys_all_sessions where curr_tid is not null order by trans_start_t limit 5;查看连接内高的SQL
sql
select t1.mem_size,* from sys_sessions t1 left join sys_thd_session t2 using (nodeid,session_id)
where t1.mem_size>1024*1024 and mod(t1.status,10)=4--仅限活动连接且内存大于1M
order by mem_size desc limit 10;系统公共内存分析
刷新内存监控数据,观察是否存在内存持续增加
sql
SQL> select *,(targ_value::bigint/1024/1024)||'M' from sys_monitors where targ_name like '%mem%' order by targ_value::bigint desc;
+-----------------+---------------------+----------------------+----------------------+
| NODEID(INTEGER) | TARG_NAME(CHAR(16)) | TARG_VALUE(CHAR(32)) | EXPR1(VARCHAR) |
+-----------------+---------------------+----------------------+----------------------+
| 1 | CATA_MEM | 21495880 | 20.50006866455078M |
| 1 | MSG_MEM | 20971520 | 20M |
| 1 | G_MEM | 16777216 | 16M |
| 1 | MODI_MEM | 8388608 | 8M |
| 1 | NET_MEM | 4194304 | 4M |
| 1 | PROC_MEM | 4194304 | 4M |
| 1 | ENCRYPTOR_MEM | 2097152 | 2M |
| 1 | TASK_MEM | 2097152 | 2M |
| 1 | TRAN_MEM | 2097152 | 2M |
| 1 | GLOCK_MEM | 1048576 | 1M |
| 1 | LOCK_MEM | 1048576 | 1M |
| 1 | DLCHK_MEM | 65624 | 0.06258392333984375M |
+-----------------+---------------------+----------------------+----------------------+
--各类内存监控项;
--等价于上面sql,格式化输出内存大小(可把格式化封装为 size_format 函数后使用)
SQL> select *,
case
when targ_value::bigint>1024*1024*1024 then (targ_value::bigint/1024/1024/1024)||'G'
when targ_value::bigint>1024*1024 then (targ_value::bigint/1024/1024)||'M'
when targ_value::bigint>1024 then (targ_value::bigint/1024)||'K'
else targ_value end MSIZE
from sys_monitors where targ_name like '%mem%'
order by targ_value::bigint desc ;
+-----------------+---------------------+----------------------+--------------------+
| NODEID(INTEGER) | TARG_NAME(CHAR(16)) | TARG_VALUE(CHAR(32)) | MSIZE(VARCHAR) |
+-----------------+---------------------+----------------------+--------------------+
| 1 | CATA_MEM | 21495880 | 20.50006866455078M |
| 1 | MSG_MEM | 20971520 | 20M |
| 1 | G_MEM | 16777216 | 16M |
| 1 | MODI_MEM | 8388608 | 8M |
| 1 | NET_MEM | 4194304 | 4M |
| 1 | PROC_MEM | 4194304 | 4M |
| 1 | ENCRYPTOR_MEM | 2097152 | 2M |
| 1 | TASK_MEM | 2097152 | 2M |
| 1 | TRAN_MEM | 2097152 | 2M |
| 1 | GLOCK_MEM | 1048576 | 1024K |
| 1 | LOCK_MEM | 1048576 | 1024K |
| 1 | DLCHK_MEM | 65624 | 64.0859375K |
+-----------------+---------------------+----------------------+--------------------+
--各类内存监控项;查询集群中节点运行状态以及数据存储信息
sql
SQL> select node_id 节点号,node_Ip 节点IP,decode(node_type,29,'主M',31,'副M','工作节点') 节点类型,
decode(node_state,2,'Working',4,'Deaded') 节点状态,store_num 存储数,major_num 主版本数
from sys_clusters;
+-----------------+-----------------+-------------------+-------------------+-----------------+-------------------+
| 节点号(INTEGER) | 节点IP(VARCHAR) | 节点类型(VARCHAR) | 节点状态(VARCHAR) | 存储数(INTEGER) | 主版本数(INTEGER) |
+-----------------+-----------------+-------------------+-------------------+-----------------+-------------------+
| 1 | 0.0.0.0:0 | 主M | Working | 93 | 93 |
+-----------------+-----------------+-------------------+-------------------+-----------------+-------------------+查询集群中各节点上的连接信息,并对活动连接执行命令时长进行排序
sql
SQL> select nodeid 节点号,user_name 访问用户,ip 访问IP,db_name 登录库名,start_t 登录时间,
decode(status,112,'IDLE',114,'Running','Other') 运行状态,auto_commit 自动提交,curr_tid 当前事务号,
trans_start_t 事务开始时间,sysdate-trans_start_t 事务执行时长
from sys_all_sessions order by 事务执行时长 desc limit 5 ;
+-----------------+------------------------+----------------------+------------------------+--------------------------+-------------------+-------------------+--------------------+--------------------------+-----------------------------+
| 节点号(INTEGER) | 访问用户(VARCHAR(128)) | 访问IP(VARCHAR(128)) | 登录库名(VARCHAR(128)) | 登录时间(DATETIME) | 运行状态(VARCHAR) | 自动提交(BOOLEAN) | 当前事务号(BIGINT) | 事务开始时间(DATETIME) | 事务执行时长(NUMERIC(38,6)) |
+-----------------+------------------------+----------------------+------------------------+--------------------------+-------------------+-------------------+--------------------+--------------------------+-----------------------------+
| 1 | SYSDBA | 192.168.2.236 | SYSTEM | 2025-07-10 13:47:49.000 | Running | T | 282002 | 2025-07-10 16:55:44.000 | 0.000004952928241 |
+-----------------+------------------------+----------------------+------------------------+--------------------------+-------------------+-------------------+--------------------+--------------------------+-----------------------------+
SQL> select nodeid,user_name,ip,db_name,start_t,status,auto_commit,curr_tid,trans_start_t,sysdate-trans_start_t trans_exec_t from sys_all_sessions order by trans_exec_t desc limit 5;
+-----------------+-------------------------+------------------+-----------------------+--------------------------+-----------------+----------------------+------------------+--------------------------+-----------------------------+
| NODEID(INTEGER) | USER_NAME(VARCHAR(128)) | IP(VARCHAR(128)) | DB_NAME(VARCHAR(128)) | START_T(DATETIME) | STATUS(INTEGER) | AUTO_COMMIT(BOOLEAN) | CURR_TID(BIGINT) | TRANS_START_T(DATETIME) | TRANS_EXEC_T(NUMERIC(38,6)) |
+-----------------+-------------------------+------------------+-----------------------+--------------------------+-----------------+----------------------+------------------+--------------------------+-----------------------------+
| 1 | SYSDBA | 192.168.2.236 | SYSTEM | 2025-07-10 13:47:49.000 | 114 | T | 282003 | 2025-07-10 16:56:02.000 | 0.000000094212963 |
+-----------------+-------------------------+------------------+-----------------------+--------------------------+-----------------+----------------------+------------------+--------------------------+-----------------------------+查询集群各节点的磁盘读写、网络读写以及事务号差值
sql
SQL> select nodeid , disk_r_n , disk_r_bytes, disk_w_n , disk_w_bytes , net_r_bytes,
net_w_bytes , min_trans_id , max_trans_id , max_trans_id-min_trans_id 事务号差
from sys_all_run_info;
+-----------------+------------------+----------------------+------------------+----------------------+---------------------+---------------------+----------------------+----------------------+------------------+
| NODEID(INTEGER) | DISK_R_N(BIGINT) | DISK_R_BYTES(BIGINT) | DISK_W_N(BIGINT) | DISK_W_BYTES(BIGINT) | NET_R_BYTES(BIGINT) | NET_W_BYTES(BIGINT) | MIN_TRANS_ID(BIGINT) | MAX_TRANS_ID(BIGINT) | 事务号差(BIGINT) |
+-----------------+------------------+----------------------+------------------+----------------------+---------------------+---------------------+----------------------+----------------------+------------------+
| 1 | 8159 | 66838528 | 10608 | 86900736 | 0 | 0 | 282004 | 282005 | 1 |
+-----------------+------------------+----------------------+------------------+----------------------+---------------------+---------------------+----------------------+----------------------+------------------+查询各节点表空间是否有出错
sql
select * from sys_all_tablespaces where media_error='T';查看连接信息表与事务运行表,确认是否存在长时间挂起事务,或持有对象资料的连接
sql
SELECT * FROM SYS_ALL_SESSIONS WHERE UPPER(SQL) LIKE '%SYS_NOTICE%';
SQL> SELECT * FROM SYS_ALL_THD_SESSION WHERE UPPER(SQL) LIKE '%SYS_NOTICE%';
+-----------------+-----------------+----------------+------------------+---------------------+-------------------+-------------------------+--------------------------+-------------------------------------------------------------------------+
| NODEID(INTEGER) | THD_ID(INTEGER) | STATE(INTEGER) | CURR_TID(BIGINT) | SESSION_ID(INTEGER) | DATABASE(INTEGER) | USER_NAME(VARCHAR(128)) | VISIT_T(DATETIME) | SQL(VARCHAR) |
+-----------------+-----------------+----------------+------------------+---------------------+-------------------+-------------------------+--------------------------+-------------------------------------------------------------------------+
| 1 | 11846 | 19 | 282007 | 3157 | 1 | SYSDBA | 2025-07-10 16:56:57.000 | SELECT * FROM SYS_ALL_THD_SESSION WHERE UPPER(SQL) LIKE '%SYS_NOTICE%'; |
+-----------------+-----------------+----------------+------------------+---------------------+-------------------+-------------------------+--------------------------+-------------------------------------------------------------------------+查询各节点工作连接数
sql
SQL> select nodeid,count(*) conn_num from sys_all_sessions group by nodeid order by conn_num desc;
+-----------------+------------------+
| NODEID(INTEGER) | CONN_NUM(BIGINT) |
+-----------------+------------------+
| 1 | 1 |
+-----------------+------------------+
--查询各节点上的连接数
SQL> select nodeid,ip,count(*) conn_num from sys_all_sessions where curr_tid is not null group by nodeid,ip order by nodeid,ip;
+-----------------+------------------+------------------+
| NODEID(INTEGER) | IP(VARCHAR(128)) | CONN_NUM(BIGINT) |
+-----------------+------------------+------------------+
| 1 | 192.168.2.236 | 1 |
+-----------------+------------------+------------------+
--查看当前节点的连接数
SQL> select nodeid,ip,count(*) conn_num from sys_all_sessions where nodeid in (9,10,11,12) group by nodeid,ip order by conn_num desc;
+-----------------+------------------+------------------+
| NODEID(INTEGER) | IP(VARCHAR(128)) | CONN_NUM(BIGINT) |
+-----------------+------------------+------------------+
+-----------------+------------------+------------------+
--查看节点号9-12的连接数
SQL> select nodeid,count(*) conn_num from sys_all_sessions where nodeid in (13,14,15,16) group by nodeid order by conn_num desc;
+-----------------+------------------+
| NODEID(INTEGER) | CONN_NUM(BIGINT) |
+-----------------+------------------+
+-----------------+------------------+
--查看节点号13-16的连接数
SQL> select nodeid,user_name,count(*) conn_num from sys_all_sessions where nodeid in (9,10,11,12) group by nodeid,user_name order by conn_num desc;
+-----------------+-------------------------+------------------+
| NODEID(INTEGER) | USER_NAME(VARCHAR(128)) | CONN_NUM(BIGINT) |
+-----------------+-------------------------+------------------+
+-----------------+-------------------------+------------------+
--查看节点号9-12的连接数查询单版本、多版本存储数(单位TB)
sql
SQL> select sum(major_num)*8/1024/1024 from sys_clusters;
+----------------------+
| EXPR1(NUMERIC(38,6)) |
+----------------------+
| 0.00070953369141 |
+----------------------+
SQL> select node_id,store_num*8/1024/1024 as TB from sys_clusters;
+------------------+--------------+
| NODE_ID(INTEGER) | TB(DOUBLE) |
+------------------+--------------+
| 1 | 7.095337e-04 |
+------------------+--------------+查看慢SQL最大耗时
sql
select sysdate as query_time,db_name,user_name,ip,(unix_timestamp(sysdate)-unix_timestamp(trans_start_t))/1000 as sql_exec_time from sys_all_sessions where user_name='sysdba' and ip='127.0.0.1' and db_name = 'SYSTEM' ;仅修改年月,不改动“日”
日期字段 = TO_DATE(('2021' || '-' || '12' || '-' || GETDAY(日期字段)), 'YYYY-MM-DD')
把天取出来跟年月去拼接再更新。
如何查询表的关联关系
以外键参照关系为实例,查询表之前的关联关系。
sql
-- 其中第一列为外键表,第二列为外键表引用的主键表
select ut1.table_name as fk_name,ut2.table_name as pk_name
from
user_constraints uc
join
user_tables ut1
on
uc.table_id=ut1.table_id
join
user_tables ut2
on
uc.ref_table_id=ut2.table_id;诊断、运维与性能
CONCAT 与 FIELD 兼容性
| 函数 | V12 状态 |
|---|---|
CONCAT(a,b,c,…) | 已支持 多参数 |
FIELD(expr,v1,v2,…) | 已支持(MySQL 兼容) |
ROWPOS 定位存储块示例
- 创建一张表,插入数据(100W),并查询该表的所有存储号。
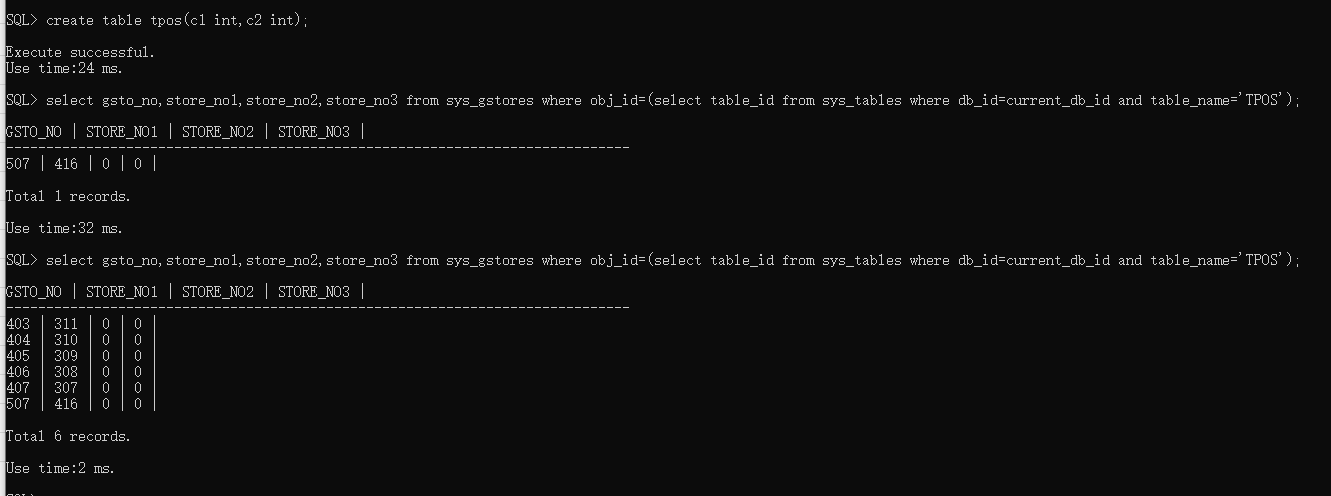 图1 所有存储号
图1 所有存储号- 通过rowpos计算行数据所在的存储块号(c1为100和800000的数据行分别位于507和406两个存储块上)
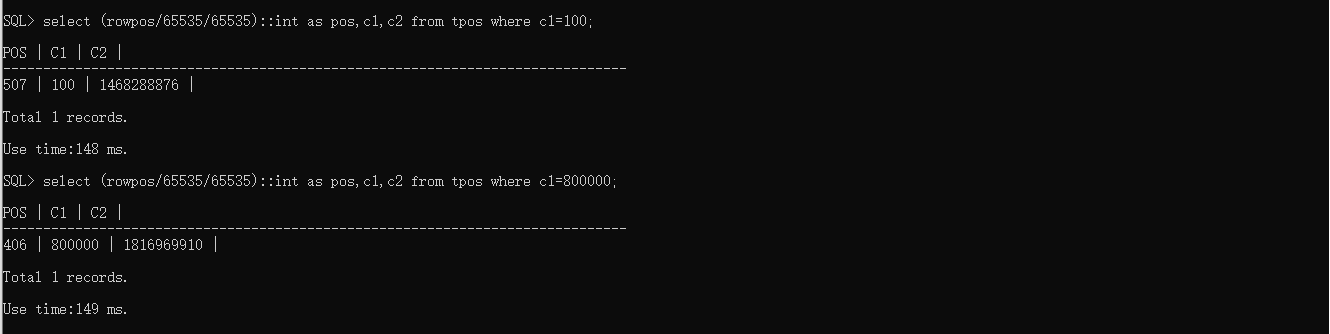 图2 数据所在存储号
图2 数据所在存储号错误码屏蔽 (SET EXCLUDE_ERRNO)
- 取消某个错误屏蔽
- 取消所有错误屏蔽
sql
-- 查看屏蔽列表:
SHOW EXCLUDE_ERRNO
-- 错误码查询
SELECT * FROM SYS_ERR_DEFS;
-- 屏蔽记载(90 为语法错误,12 为违反唯一值约束):
--通过多次执行屏蔽记载语句,实现多个错误屏蔽
SET EXCLUDE_ERRNO TO 12
SET EXCLUDE_ERRNO TO 90
-- 取消屏蔽:
-- 方法一:取消某个错误屏蔽,设置为对应错误码负值
SET EXCLUDE_ERRNO TO -90
--方法二: 如果需要取消所有屏蔽,清空屏蔽列表,设置为0
SET EXCLUDE_ERRNO TO 0V11版本drop table if exists table_name删除表报错不支持
V11版本不支持if exists的方式drop表,目前只有V12版本支持该用法。
V11版本可以先查询系统表,结果为空则为不存在,再选择是否删表。
select schema_name,table_name from all_tables t inner join all_schemas s on t.schema_id=s.schema_id where table_name='table_name';
虚谷是否支持前缀索引
目前没有支持前缀索引,可以将索引字段精度过长的改为varchar变长来进行创建。
精度是怎么换算的,有没有计算公式,比如我numeric设置的是32,但实际查出来的是一个不同的数字
sql
select case type_name when 'NUMERIC' then trunc(scale/65536)::int else null end as acc,mod(scale,65536) as scale from all_columnssql查询出来的数据如何给行加一个排序序号的数据列
可以使用rownum做一次子查询来排序筛选出的十条数据。
sql
SELECT * FROM (SELECT rownum,* FROM table_name WHERE rownum <=10) t ORDER BY t.rownum desc;